We are excited to announce Vectroid, a serverless vector search solution that delivers exceptional accuracy and low latency in a cost effective package. Vectroid is not just another vector search solution—it’s a search engine that performs and scales in all scenarios.
Why we built Vectroid
Talk to any team working with large, low latency vector workloads and you’ll hear a familiar story: something always has to give. Vector databases often make significant tradeoffs between speed, accuracy, and cost. That’s the nature of the mathematical underpinnings of vector search works—taking algorithmic shortcuts to get near-perfect results in a short amount of time.
There are some common permutations of these tradeoffs:
Based on the existing vector database landscape, it would seem that building a cost effective vector database requires sacrificing either speed or accuracy at scale. We believe that’s a false pretense: building a cost-efficient database is possible with high accuracy and low latency. We just need to rethink our underlying mechanism.
Our “aha” moment
Query speed and recall are largely a function of the chosen ANN algorithm. Algorithms which are both fast and accurate like HNSW (Hierarchical Navigable Small Worlds) are memory intensive and expensive to index. The traditional assumption is that these types of algorithms are untenable for a cost-conscious system.
We had two major realizations which challenged this assumption.
- Demand for in-memory HNSW is not static. Real world usage patterns are bursty and uneven. A cost efficient database can optimize for this reality by making resource allocation dynamic and by individually scaling system components as needed.
- HNSW’s memory footprint is tunable. It can be easily be flattened (ex. by compressing vectors using quantization) and expanded (ex. by increasing layer count), which gives us the flexibility to experiment with different configurations to find a goldilocks setup.
What is Vectroid?
Vectroid is a serverless vector database with premium performance. It delivers the same or stronger balance of speed and recall promised by high-end offerings, but costs less than competitors.
- Performant vector search: HNSW for ultra fast, high recall similarity search.
- Near real-time search capabilities: Newly ingested records are searchable almost instantly.
- Massive scalability: Seamlessly handles billions of vectors in a single namespace.
- Cost efficient resource utilization: Scaling each layer (ingest, index, query) separately.
How Vectroid performs
The core philosophy of Vectroid is that optimizing for one metric at any cost to the others doesn’t make for a robust system. Instead, vector search should be designed for balanced performance across recall, latency, and cost so users don’t have to make painful tradeoffs as workloads grow.
When tested against other state-of-the-art vector search, Vectroid is not only competitive but the most consistent across the board. Across all of our tests, Vectroid is the only databases that was able to maintain over 90% recall while scaling to 10 query threads per second—all while maintaining good latency scores.
Some early benchmarks:
We’ll be releasing the full benchmark suite (with setup details so anyone can reproduce them) in an upcoming post. For now, these numbers highlight the kind of scale and performance we designed Vectroid to handle.
How Vectroid works
Vectroid is composed of two independently scalable microservices for writes and reads.
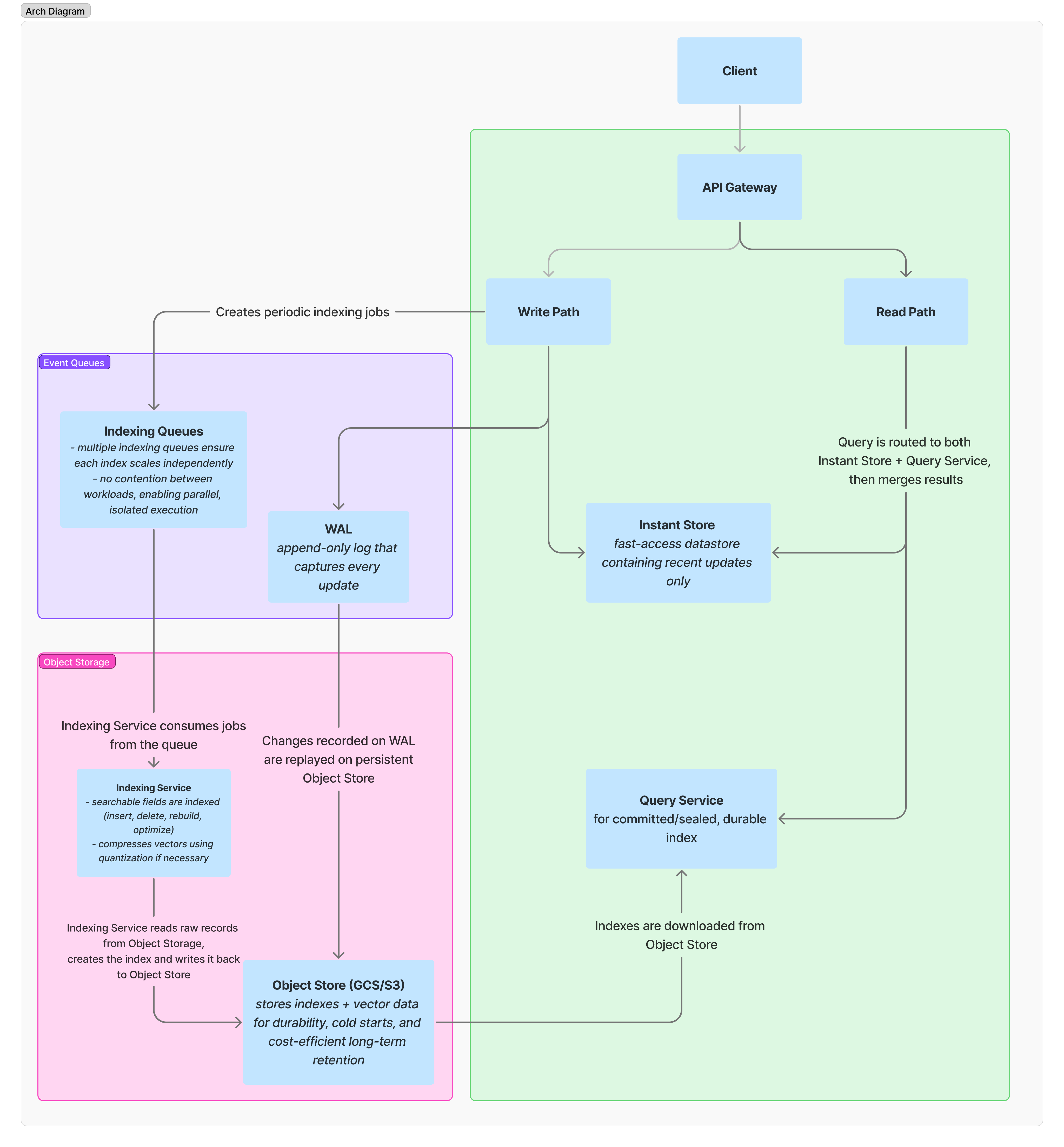
As the diagram shows, index state, vector data, and metadata are persisted to cloud object storage (GCS for now, S3 coming soon). Disk, cache, and in-memory storage layers each employ a usage-aware model for index lifecycle in which indexes are lazily loaded from object storage on demand and evicted when idle.
For fast, high-recall ANN search, we chose the HNSW algorithm. It offers excellent latency and accuracy tradeoffs, supports incremental updates, and performs well across large-scale workloads. To patch its limitations, we added a number of targeted optimizations:
Final Thoughts
We’re just getting started. If you’re building applications that rely on fast, scalable vector search (or you’re running up against the limits of your current stack), we’d love to hear from you. Start using Vectroid today or sign up for our newsletter to follow along as we continue building.

Written by Talip Ozturk
Founder of Vectroid